【AWSハンズオン】「Amazon Kendraで簡単に検索システムを作ろう!」をやってみた
はじめに
今回は2023年に公開されたAmazon Kendraの入門編ハンズオンに取り組んでみたので、そちらの情報を共有したいと思います。
ハンズオンは以下リンクから申し込みできます。
ご参考までに、当ハンズオンが公開された記事のリンクも載せておきます。
Amazon Kendra 入門ハンズオンを公開しました!– AWS Hands-on for Beginners Update | Amazon Web Services ブログ
なお本記事ではハンズオンの内容やKendraの仕様について細かめに記載しているため、多少長い記事となっています。全て読んでいただけると嬉しいですが、お時間が少ない場合には目次からご興味のある内容まで飛んでいただければと思います。
前提条件
今回実施者はPowerUserAccessとIAMFullAccessを持ったIAMユーザーで作業を行いました。ハンズオンの一部でIAMロールを新たに作成する必要があるため、基本的なAWSサービスに対する操作ができる権限+IAMロールを作成する権限を持ったIAMユーザーの準備が必要です。
Amazon Kendraとは
そもそもAmazon Kendraとはどういったサービスなのかについて最初に触れておきたいと思います。
Amazon Kendraとは「機械学習を活用したインテリジェントなエンタープライズ検索で回答を迅速に見つける」ことができるサービスです。つまり、機械学習を用いて社内のドキュメント等の検索システムを構築することができるようになるということです。
基本的な概念として、Amazon Kendraでは「インデックス」と呼ばれる索引を作成し、どこに何のデータがあるのかを管理しています。また検索をかけるデータソースに対してアクセス制御を行う事も可能で、「○○部門の人しかアクセスできないデータソース」等の設定も行えるようです。(今回のハンズオンではそこまで対応していないので、実際の設定方法等は未記載です。)
実運用としては下記画像のように基盤モデルと呼ばれるLLM(Large Language Model)と組み合わせて、「生成AIとして質問をしたら、社内ドキュメント類から最適解を検索して流暢な日本語で回答してくれる」ようなシステムを構築することも検討できます。
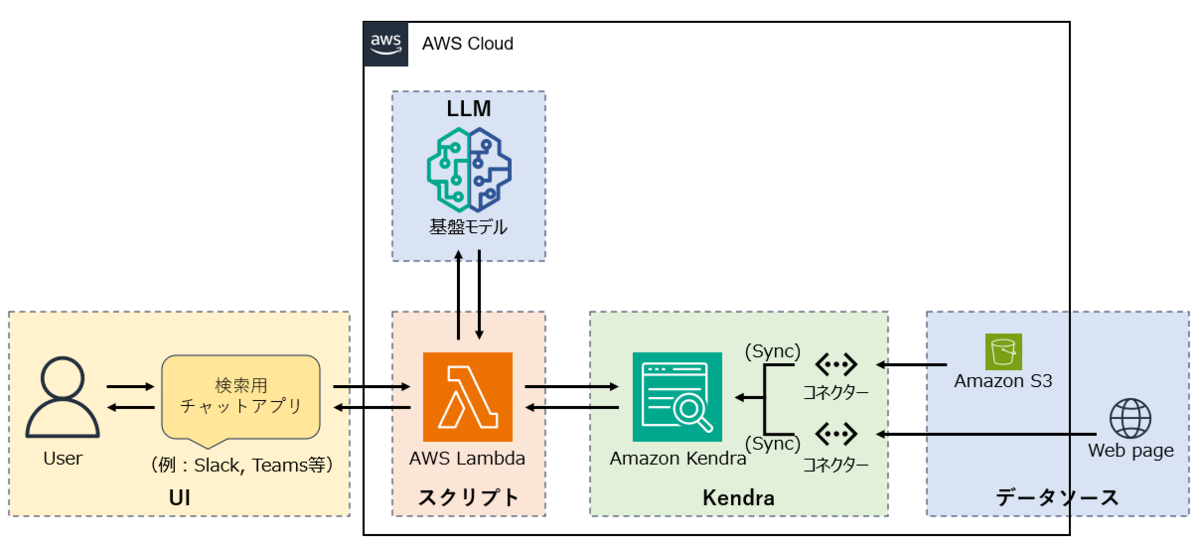
ハンズオン概要
今回のハンズオンではまず下記図のような小規模検索システムを構築しました。

作業の大きな流れとしては以下のようになります。
1. インデックスの作成
2. データソースの追加
3. 追加されたデータソースから情報をSync
4. 検索
5. 応用編)Webアプリケーションのデプロイ
また、今回のハンズオンは2種類のデータソースを設定する流れとなっており、
① S3バケットをデータソースとする例
② Webページをデータソースとする例
の2種類を使用した構築ハンズオンです。インデックスは同じものを使いながら、検索をかけるデータソースとしてS3やWebページを追加するという流れです。
初心者向けのハンズオンとしては、まずKendraにデータソースからSyncした情報を基にAWS Management Console上のKendra検索画面にて検索結果を表示するというシンプルな形となっています。

その後、応用編としてWebアプリケーションを構築し、アプリケーションから検索をかけるというハンズオンを行います。
進め方としては基本的にハンズオン公式のWebサイト上に貼り付けられているYoutube動画の説明通りに進めていきます。
ハンズオンの内容
1. インデックスの追加
Kendraで検索をかけるための索引を準備するため、Management Consoleでインデックスを作成します。この際に新しくIAMロールを作成した(Create a new roleを選択することで自動生成される)のですが、内容を確認したみたところ主にCloudWatch Logsへの書き込みを行う権限を付与しているようでした。以下が実際のJSONです。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"cloudwatch:PutMetricData"
],
"Resource": "*",
"Condition": {
"StringEquals": {
"cloudwatch:namespace": "AWS/Kendra"
}
}
},
{
"Effect": "Allow",
"Action": [
"logs:DescribeLogGroups"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup"
],
"Resource": [
"arn:aws:logs:us-east-1:<アカウントID>:log-group:/aws/kendra/*"
]
},
{
"Effect": "Allow",
"Action": [
"logs:DescribeLogStreams",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": [
"arn:aws:logs:us-east-1:<アカウントID>:log-group:/aws/kendra/*:log-stream:*"
]
}
]
}その他にも以下のような設定ができるようでした。
- インデックスの中身を暗号化するための暗号化キー指定
- デフォルトでもKendraのデフォルトキーを使って暗号化されるため、事前に用意が無くてもインデックス作成は可能
- アクセスコントロールリストの作成、及びIAM Identity Centerの利用
- エディションの選択(Developer Edition or Enterprise Edition)
- Developer Edition:検証目的で利用(本番環境には不向き)
- Enterprise Edition:本番ワークロードで利用(Developer Editionと比べて接続できるデータソースの数が多く、可用性も高い)
今回のハンズオンでは検証目的のため暗号化や認証の追加設定はせず、Developer Editionにて実施しました。
筆者が本ハンズオンを行った際インデックスの作成は数分で完了しましたが、解説動画にて説明されている通り、インデックスの作成には最大30分程度かかることもあるようです。索引としてインデックスを作成して、そのインデックスに対してデータソースを登録・Syncしていく流れなので、この段階では索引から検索をかけるデータの器を作っているイメージだと考えています。
詳しくは公式ドキュメントに記載されているインデックスの説明をご覧ください。
2. データソースの追加
続いてインデックスにデータソースから内容を取り込む作業を行います。今回のハンズオンではPDF化されたAWS公式ドキュメントの一部をS3に格納しインデックスに取り込むパターンと、Webページの内容をインデックスへ取り込むパターンの合計2パターンを実施しました。
インデックスに取り込むデータソースの選択画面では、ハンズオンで利用するデータソース以外にも様々なサービスへのコネクターが用意されていました。

(例:RDSやS3等の各種AWSサービス、Box、Dropbox、Google Drive、OneDrive、Slack、etc.)
参考リンク:Kendraがサポートしているデータソース
このデータソース選択画面にて取り込みたいデータ元を選択し、詳細を設定して実際にデータをSyncする準備を行います。データソースとして取り込む対象ドキュメントの言語指定やIAMロールの指定、VPCの設定(VPCを介したデータソースへのアクセスが必要な場合に使用)等を行うことができます。
このステップでのIAMロールは、インデックス作成時に新規作成したIAMロールとは別物となります。S3をデータソースとするパターンでの実際のJSONを見てみると、S3に対するGetやListアクションに加え、Kendraに対するBatchPutDocumentやBatchDeleteDocumentアクションを許可しているようです。
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::<S3バケット名>/*"
],
"Effect": "Allow"
},
{
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::<S3バケット名>"
],
"Effect": "Allow"
},
{
"Effect": "Allow",
"Action": [
"kendra:BatchPutDocument",
"kendra:BatchDeleteDocument"
],
"Resource": "arn:aws:kendra:us-east-1:<アカウントID>:index/<インデックスUniqueID>"
}
]
}Webページをデータソースとする場合のIAMロールでは、S3やKendraに対する許可に加えてSecretsManagerやKMS、EC2等の権限も付与されていました。
また基本的な設定に加え、以下の設定ができるようです。
S3がデータソースの場合:
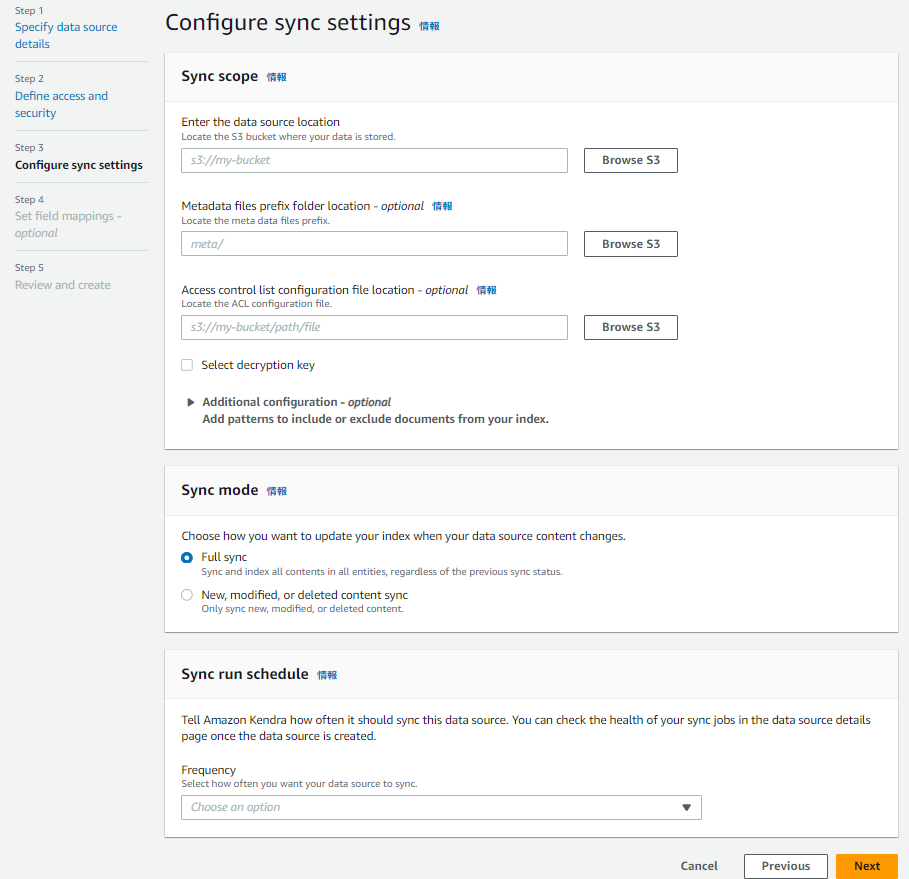
- データソースの詳細設定
- 実際にデータソースとして取り込むS3バケットを指定する
- Metadataファイルの指定
- データソースに付加情報を与え、特定の情報からのみ検索をかけるといった追加設定を行う(議事録からのみ検索させる等)
- Access Control Listの指定
- ユーザーやグループに対してアクセス制御を行う設定を追加する(運用者のみがアクセスできるデータソース、管理者のみがアクセスできるデータソース等)
- Sync方法の指定
- 全量Syncを行うか、前回Syncとの差分のみSyncを行うか等を設定する
- Syncスケジュールの設定
- Kendraがデータソースからデータを取り込む頻度についてスケジュール化して設定する(On-demand、Hourly、Daily、Weekly、Monthly、Custom等)
Webページがデータソースの場合:
- ソースURLの指定
- 認証設定
- Webページにアクセスするために認証が必要な場合は設定を行う
- Webプロキシ設定
- プロキシを指定する必要がある場合は、ホスト名やポート番号等を指定する
- Syncスコープの指定
- その他Syncスコープの詳細設定
- 上記スコープの指定に加えて更に詳細な設定を行う
- Sync方法の指定
- 全量Syncを行うか、前回Syncとの差分のみSyncを行うか等を設定する
- Syncスケジュールの設定
- Kendraがデータソースからデータを取り込む頻度についてスケジュール化して設定する(On-demand、Hourly、Daily、Weekly、Monthly、Custom等)
初期設定画面上で利用する目的や用途によって細かな設定を行うことができるようになっていました。今回のハンズオンではシンプルにS3やWebページをデータソースとして、On-demandでSyncを行う形で設定を行いました。
3. データのSync
前述の通り本ハンズオンではOn-demandでデータをSyncする設定を行ったため、データソースとしてS3バケットやWebページの追加が完了したら実際にSyncしていきます。
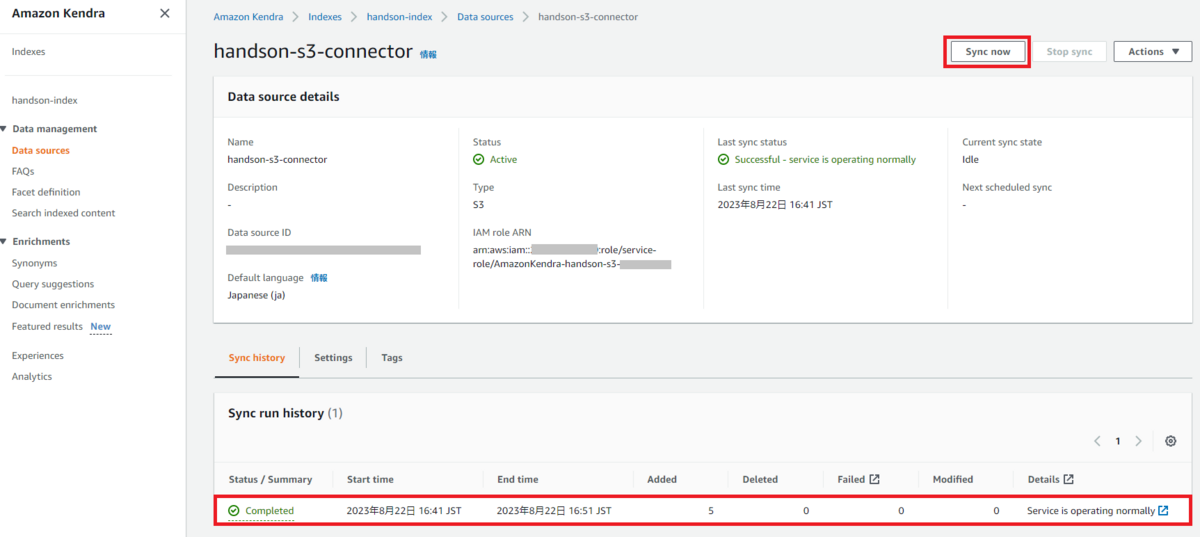
インデックスに対してデータのSyncを行うことで、毎回データソース元に検索をかけるのではなく、Kendraがデータソースのドキュメントを整理した索引(=インデックス)を活用して迅速に検索を行えるようにしている形だと理解しています。
今回S3がデータソースの場合(量がそこまで多くないPDFファイル5つのみのSync)は数分で完了しましたが、Webページがデータソースの場合(2つのURLをSync)は15分~20分程度かかりました。場合によっては少量のデータSyncでも数十分から数時間かかることもあるようです。実際に検索システムとして構築する際には膨大なデータソースから検索をかけることが予想されるため、その際Syncにどれだけ時間がかかるのか少し懸念が残ります。
4. 検索
インデックスへデータソースからのデータSyncが完了したら、実際にManagement Console上のKendra検索ページから検索をかけることができます。基本的なUIとしては普段使うGoogle等の検索エンジンと大差ないですが、1つ注意点があります。
前述の通りデータソースを指定する際に標準言語も指定をするのですが、検索画面でも正しい言語を指定する必要があります。今回データソースとして指定したS3バケット内のドキュメントやWebページは日本語のため、検索画面の言語設定も日本語になっていないと検索結果が表示されません。
成功例:
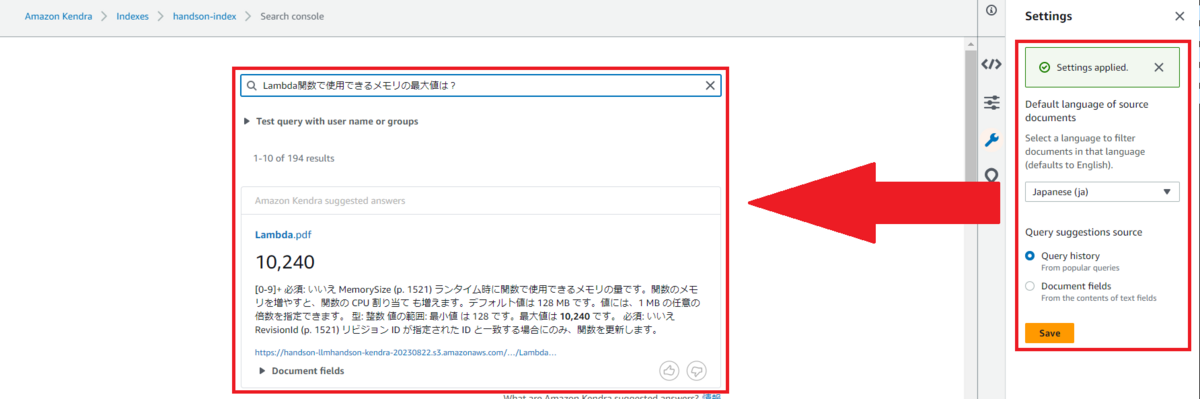
失敗例:

筆者がKendraの検索画面を操作した際には言語設定がデフォルトでEnglishとなっていたため、初回の検索が失敗しました。
5. Webアプリの構築
本ハンズオンの応用編として、Webアプリケーションの構築をCloudFormationを使用して行いました。作成したKendraのインデックスに加えてAWS AmplifyやCognitoと連携してWebアプリケーションをデプロイし検索をかけてみるといった目的となっており、基本的な構成は以下の通りです。
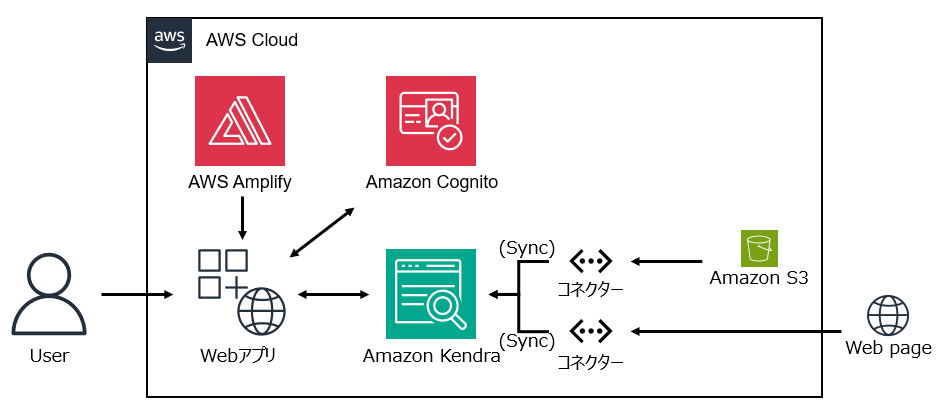
日本語での検索を行うためにCodeCommit上のコードを一部編集する必要がありますが、基本的にはCloudFormationで全て自動デプロイされます。デプロイが完了したら、実際にブラウザ経由で検索をかけてみます。
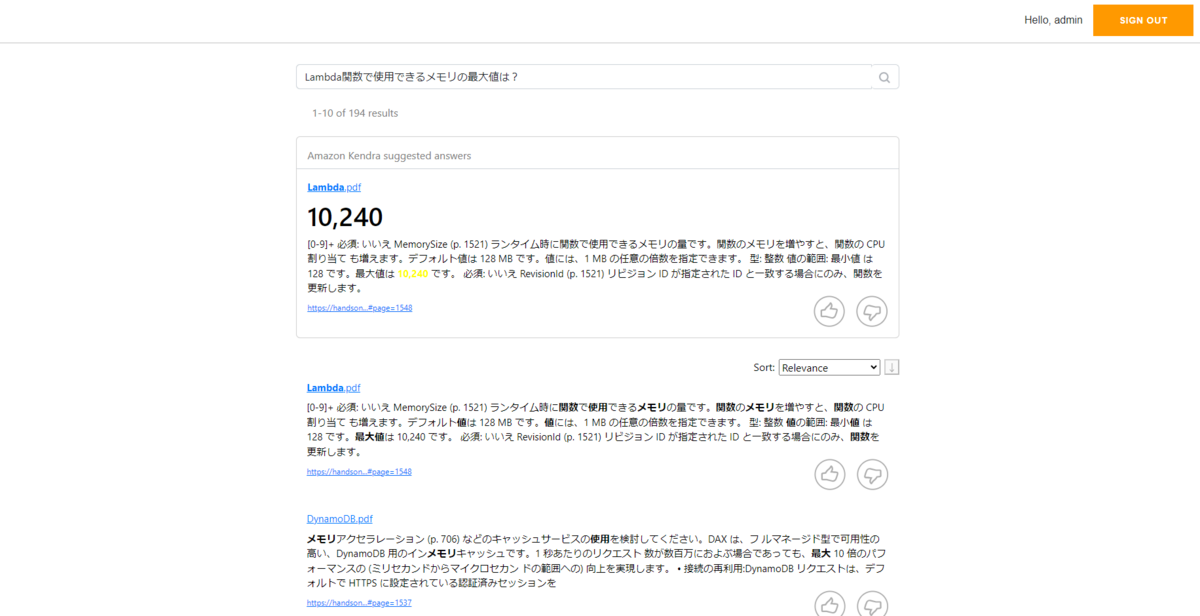
結果としてManagement Console上のKendra検索画面で検索をかけた際と同じ結果が返ってきました。本ハンズオンで構築したWebアプリケーションを利用して、Management ConsoleにログインすることなくKendraのインデックスから検索をかけられていることが分かります。また、質問に対する回答の情報源についてもリンク先へ飛ぶことで確認できるため、情報の信ぴょう性について自身で確認することもできます。
まとめ
本ハンズオンでは以下項目について実際に操作し体験できました。
- Amazon Kendraのインデックス作成
- データソースの追加とインデックスへのSync
- Management Console上で検索を実施
- Webアプリケーションをデプロイし、ブラウザ経由で検索を実施
筆者のAmazon Kendraに対する個人的な感想としては、インデックスにSyncさせるデータソースの設定方法がすごくシンプルで、かつアクセス制御や認証等の必要な機能を兼ね備えている便利なサービスという印象を受けました。AWSのみならず他のクラウドサービスプロバイダーや生成AIサービスベンダーも近しいサービスを提供していると思いますが、「AWSでのワークロードを実行していてその中のデータソースを効率的に生成AIと絡めて活用したい」といった場合には最適の実装方法かと思います。
また冒頭に記載したLLMとの連携を含めた生成AIのシステムをAWS上に構築することで、企業内でクローズドに利用できるセキュアなエンタープライズ検索システムを実装することもできると思います。
本ハンズオンはAmazon Kendraの基本的な挙動や操作について学ぶのみにとどまっていますが、今後更にKendraを活用できるよう検証していき、追加でハンズオン等出てきましたら触ってみようと思います。
以上、長い記事となりましたがお読みいただきありがとうございました。
【初心者向け】AWSのCloudShell(CLI)でIAMユーザー作成とコンソールアクセスの有効化/無効化をやってみた
- はじめに
- 前提
- 作業の流れ
- 0. 準備
- 1. IAMユーザーを所属させるIAMグループの作成とポリシーのアタッチ
- 2. IAMユーザーの作成とグループへのアタッチ
- 3. IAMユーザーのManagement Consoleアクセス有効化・無効化
- まとめ
はじめに
今回はAWSのManagement Consoleで利用できるCloudShell(CLI)にて、以下の作業を行いました。
- IAMユーザーを所属させるIAMグループの作成とポリシーのアタッチ
- IAMユーザーの作成とグループへのアタッチ
- IAMユーザーのManagement Consoleアクセス有効化・無効化

Management ConsoleにてGUIで対応することも可能ですが、IAMユーザーやIAMグループを複数作成する場合に、誤操作による設定不備が発生する可能性があります。その際にAWSが提供するCloudShell(CLI)を活用することで可能な限り誤操作を減らし、手順を簡略化しつつ再現性を高めることができると考え、以下リンク先のコマンドを元に試してみました。
参考)AWSコマンド一覧
前提
まず前提として、作業対象のAWSアカウント上でIAMの管理権限を持っているユーザーでログインすることが必要です。IAMの設定変更を行える権限を持っていないと、GUI操作と同じくエラーメッセージが返ってきてしまいます。
作業の流れ
今回は以下の流れで一連の作業を行いました。
①IAMグループ作成
②IAMグループへポリシーアタッチ
③IAMユーザー作成
④IAMユーザーをIAMグループへ所属させる
⑤IAMユーザーのコンソールアクセス有効化
⑥IAMユーザーのコンソールアクセス無効化
0. 準備
CLIでの作業を行うため、まずはAWSアカウントのManagement ConsoleにログインしてCloudShellを開きます。

※画面下部にCloudShellが埋まってしまっている場合には、必要なサイズに拡大してください。

1. IAMユーザーを所属させるIAMグループの作成とポリシーのアタッチ
まずはIAMユーザーを所属させるIAMグループの作成と、そのグループに所属しているIAMユーザーが適切な権限を持つためのポリシーをIAMグループにアタッチします。

今回の例のようにユーザー数が少ない場合にはIAMユーザーに直接ポリシーをアタッチすることも可能ですが、ユーザー数が増加するにつれてユーザー毎のポリシー管理を行う工数と時間がかかってしまうため、グループに所属させることで権限管理を確実、かつ簡易化します。
手順1.1
ReadOnlyTestGroupという名前のIAMグループを作成します。
aws iam create-group --group-name ReadOnlyTestGroup
手順1.2
ReadOnlyTestGroupにAWS管理ポリシー「ReadOnlyAccess」を付与します。
aws iam attach-group-policy --group-name ReadOnlyTestGroup --policy-arn arn:aws:iam::aws:policy/ReadOnlyAccess![]()
手順1.3(オプション)
実際にIAMグループの作成とポリシーのアタッチが完了していることを確認します。
aws iam list-attached-group-policies --group-name ReadOnlyTestGroup
※GUI操作の場合は、Management Console上でIAMを開き、左ペインから「ユーザーグループ」を選択してReadOnlyTestGroupの許可が「定義済み」となっている事を確認します。

2. IAMユーザーの作成とグループへのアタッチ
IAMグループの作成とポリシーのアタッチが完了したところで、続いてManagement Consoleにアクセスするユーザーの作成と適切なグループへのIAMユーザーのアタッチを行います。

IAMグループには複数のIAMユーザーを所属させることができ、IAMユーザーは複数のIAMグループに所属することも可能です。詳細についてはAWSの公式ドキュメントを参照ください。
手順2.1
まずはIAM管理者としてManagement ConsoleにアクセスするIAMユーザーを作成します。今回はTestUser01という名前のユーザーを、EnvironmentタグとしてTestをつけて作成します。
aws iam create-user --user-name TestUser01 --tags Key=environment,Value=Test
手順2.2
続いて、作成されたIAMユーザー(TestUser01)をReadOnlyTestGroupに所属させます。
aws iam add-user-to-group --user-name TestUser01 --group-name ReadOnlyTestGroup![]()
手順2.3(オプション)
実際にIAMユーザーがグループに所属できているかを確認します。
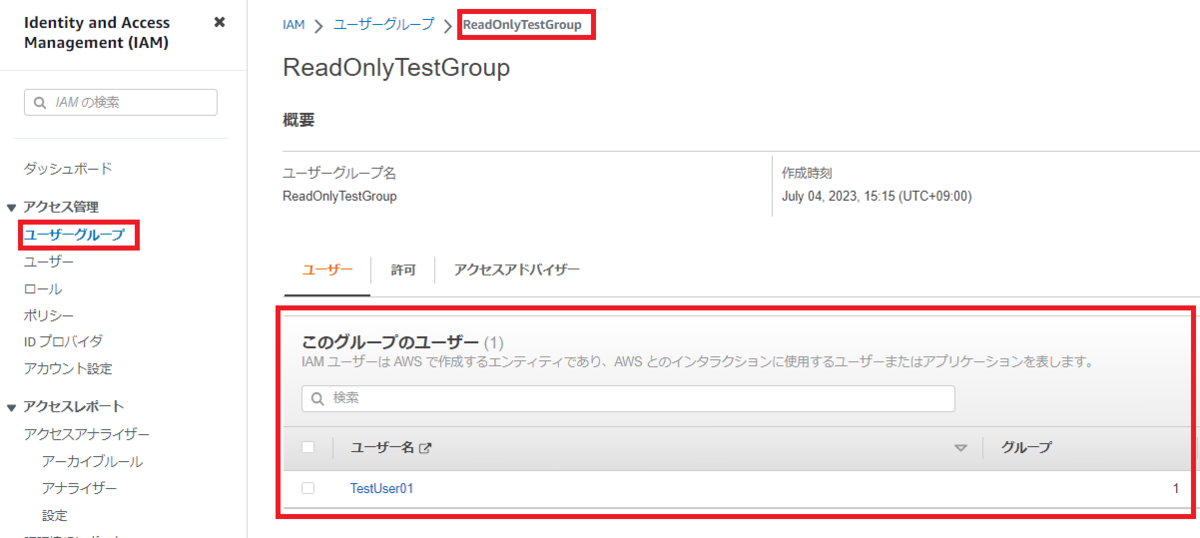
aws iam list-groups-for-user --user-name TestUser01
赤枠内にてTestUser01がReadOnlyTestGroupに所属できていることが確認できます。
※GUI操作の場合は、手順1.3と同じくユーザーグループ画面へ遷移し、ReadOnlyTestGroupを選択します。画面下部「このグループのユーザー」欄にTestUser01がリストされていることを確認します。
3. IAMユーザーのManagement Consoleアクセス有効化・無効化
最後に、作成したIAMユーザーのコンソールアクセス有効化/無効化を行います。
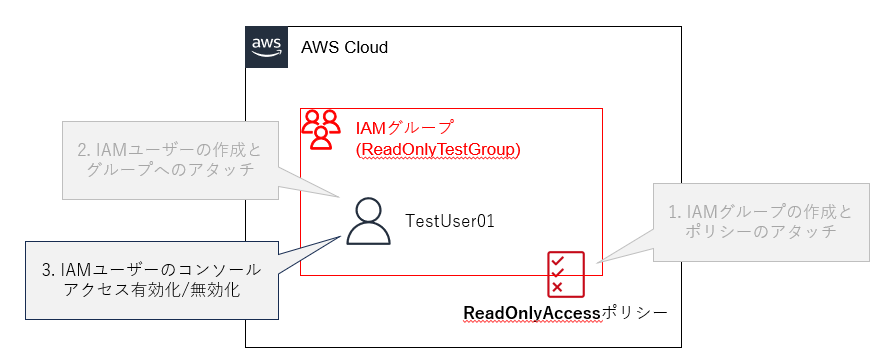
「IAMユーザーの有効化/無効化」と聞くと単純にユーザー自体を有効化/無効化すると考えますが、IAMの仕様上正しくはユーザーのコンソールログイン用パスワードの作成/削除を行います。これによりパスワード削除状態時はコンソールログインができなくなり、IAMユーザーの利用者視点ではIAMユーザーが有効化/無効化されているように見えるという仕様になっています。
この手順が活用できるユースケースとしては、「本番環境アカウントで変更作業を行えるIAMユーザーを通常時は無効化しておき、変更作業が必要な際に有効化して本番環境にて作業を実施、その後作業が完了し次第再度無効化を行う」などが考えられます。この運用を行う事により、意図しない本番環境での変更を阻止するといった効果を得ることができます。
3.1 IAMユーザーの有効化
まずはIAMユーザーのコンソールログイン用パスワードを作成(=IAMユーザーを有効化)します。
aws iam create-login-profile --user-name TestUser01 --password Testxxxxxxxxxx --password-reset-required
このコマンドでは「--password」で一時的なコンソールログイン用パスワードを作成し、その後の「--password-reset-required」を指定することでIAMユーザー初回ログイン時にパスワード変更を強制させています。これによりIAMユーザーの利用者は初回ログイン時以降、任意のパスワードを使用することができます。
※IAMユーザー利用者へコンソールログイン有効化の連絡を行う際には、上記「--password」で指定した一時的なパスワードも連携する必要があります。これが無いと初回ログイン+パスワードリセットを行えないためです。なお、連携の方法についてはセキュリティ面を考慮する必要があります。
3.1.(参考) 初回ログイン時のIAMユーザー利用者視点
IAMユーザー利用者は初回ログイン用パスワードが連携されたら、IAMユーザーとしてアカウントにサインインします。

その後、パスワードリセット画面へ遷移します。ここで新しいパスワードをセットすることで、次回ログイン時からは新しくリセットされたパスワードを利用することができるようになります。

3.2 IAMユーザーの無効化
続いてIAMユーザーのコンソールログイン用パスワードを削除(=IAMユーザーを無効化)します。
aws iam delete-login-profile --user-name TestUser01![]()
これによりコンソールログイン用パスワードが削除され、IAMユーザー利用者はコンソールにログインできなくなります。
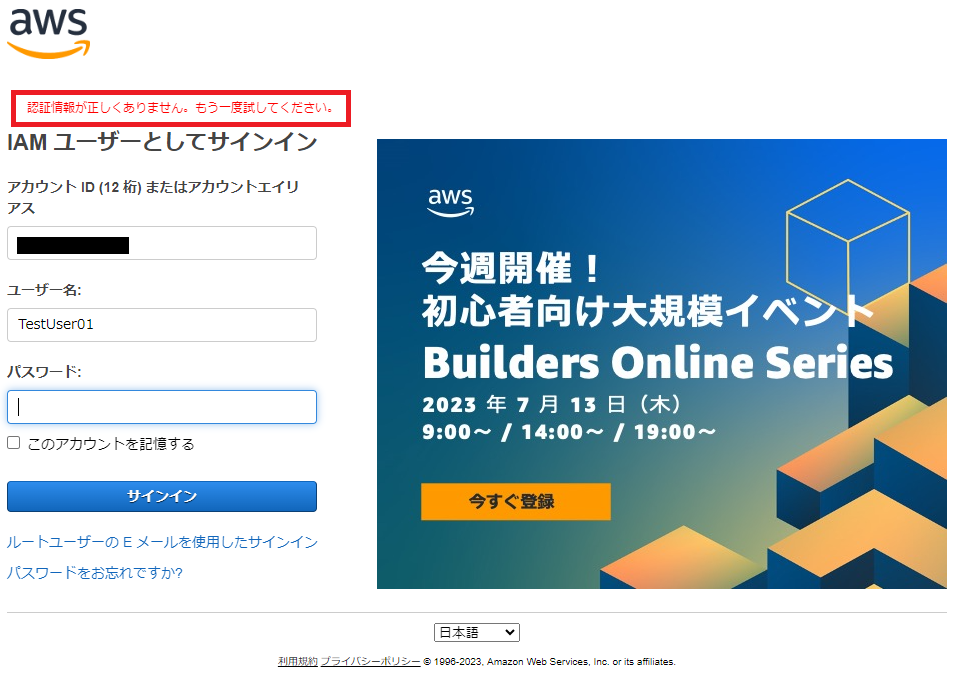
3.2.(参考) コンソールログイン用パスワード無効時のIAMユーザー利用者視点
IAMユーザー有効時にログインできていたパスワードでサインインをすると、認証情報が正しくないと表示されコンソールにアクセスできなくなります。
まとめ
今回はIAMグループの作成からポリシーのアタッチ、IAMユーザーの作成とグループへのアタッチ、IAMユーザーの有効化/無効化等基本的な作業をCloudShellで行ってみました。単純な作業のためManagement ConsoleにてGUI操作で同等作業を行うことは可能ですが、前述した通り手順の簡略化と再現性の向上を行うためにCLIを利用することも一つの手段だと思います。
またIAMユーザーの有効化/無効化を行う際には、ユーザー自体の有効化/無効化を行うのではなく、実際にはコンソールログイン用パスワードを作成/削除するというIAMの仕様についても気付く事ができました。これ以外にもユーザー視点での動作と実際のAWS内での動作に差異があることはあると考えられるため、今後も新しい気付きがあれば共有できればと思います。
ここまでご覧いただきありがとうございました。